 Well, that's no good.
And it doesn't even have proper HTTPS!
Well, that's no good.
And it doesn't even have proper HTTPS!Added on: Wednesday, 02 March, 2022 | Updated on: Friday, 13 February, 2026
I have been looking into getting into shell scripting for a long time, mostly because it's a very simple but powerful way to automate boring and tedious tasks.
One such task that I think is pretty important is archiving websites for future use. The Internet is not a static place, but rather surprisingly volatile, prone to websites suddenly (and sometimes permanently) going offline, or paywalls being constructed to make reading even one random article an exercise in frustration. As an example, I tried to find resources on how to get started with kernel development, and was able to find an interview Greg Kroah-Hartman gave on tuxradar.com, a website that seems to now return a 404 error on even it's homepage, let alone the link I found.
Well, that's no good.
And it doesn't even have proper HTTPS!
To get around this issue, I used the Internet Archive to view an archive that it had stored from 2014.
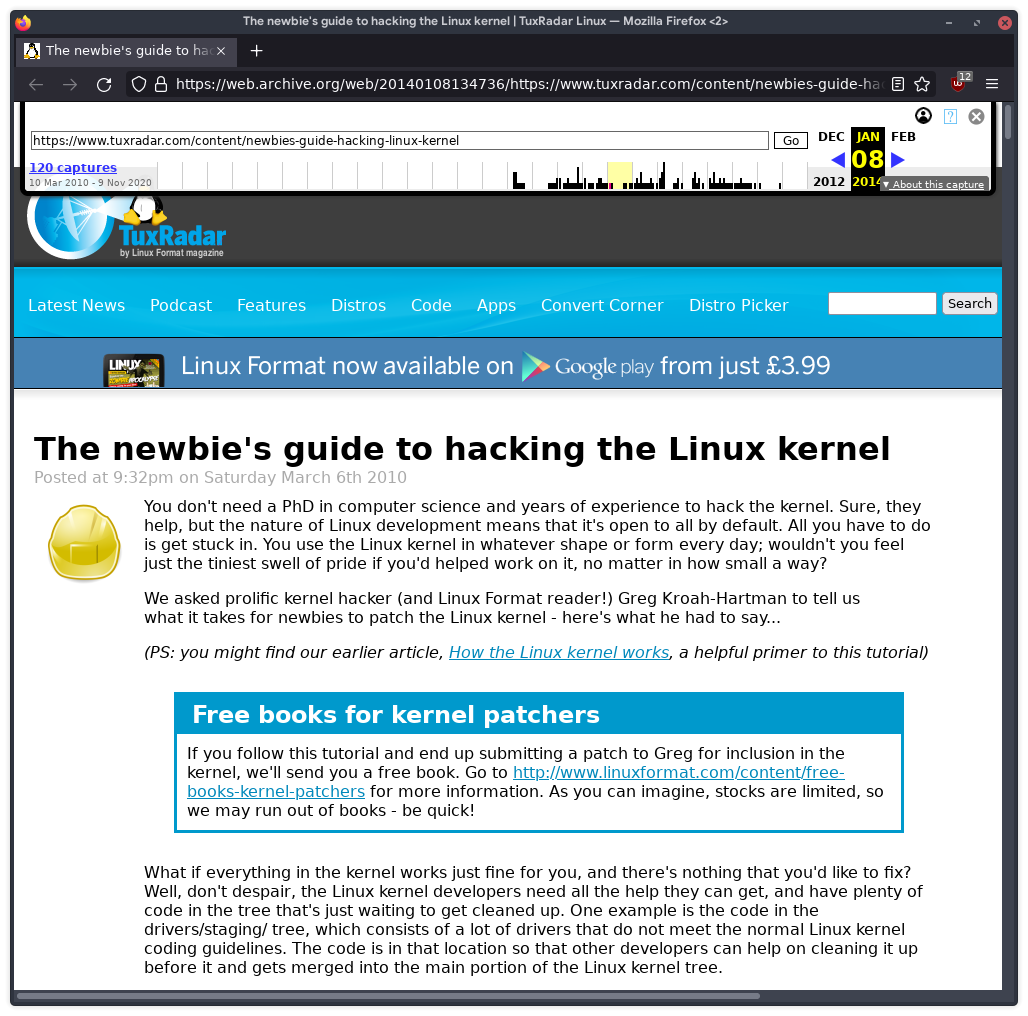 Now, that's
better. Thanks Internet Archive!
Now, that's
better. Thanks Internet Archive!
The Internet Archive is an amazing project set up to build not only just a collection of webpages from years past and years to come, but also:
Books in public domain, and some books not in the public domain can be borrowed as if from a library all around the world, free of charge
Music in the public domain
Video (includes everything from silent movies to trailers of today's blockbusters to maybe even some classics)
Video games from old consoles and PC platforms, with the permission of the rights holder, which can even be played in the browser itself or optionally be downloaded from the Internet Archive, depending on how the rights holders have configured their uploads I believe.
Even YouTube videos play using Internet Archive! I was actually
really surprised by this since YouTube doesn't
just have a <video> tag in their source code
with a URL to the video, but hey, I'm not
complaining! This is truly the cherry on top. In case YouTube ever
goes away or someone on the platform deletes a controversial video,
the proof still stays somewhere, preserved for posterity.
The Internet Archive also provides a helpful way to archive any webpages you come across as well, and this is the subject of this post.
While as of the writing of this article, my website is a bit sparse when it comes to external links, I expect this to change as time goes on. Also, I have a lot of links saved in plain text files for future reference. These are primarily resources I access from time to time, or rather information about topics I'd like to know more about. I don't really want to be in a situation where I need to access these resources only to be greeted with a 404 error.
I was looking into ways to automate saving URLs to archive.org. The preferred tool to do so is ia, which is a Python tool for interacting with the Internet Archive through the command line.
However, this tool is a bit overkill for my purposes. I really
only want one feature out of all the ones that ia
offers.
Luckily, there's a much easier, and barebones way to archive a given URL; by prefixing https://web.archive.org/save to the beginning of the URL, you can tell Internet Archive to save the URL. If, for example, you tell the service to make excessive archives, it will automatically deny the request.
So, at this point, what I really wanted was to get a bit more
familiar with shell scripting and use standard utilities to make a
script that would read the raw HTML, extract the URLs and then use
curl to send a request to the Internet Archive to
archive them.
I also didn't really want to spam them with requests, so I also added a simple sleep command to send out requests every 2 seconds.
The script just outputs the headers of the response gotten back from the Archive. If it's a 302 FOUND message, and it has a location header with a web.archive.org URL, most likely it's been archived.
The code is at this link. I initially was just going to post it here, but I decided that there were still some modifications to be made and it would be better to have them somewhere more easily updated.
It's also licensed under the public domain, so that not a single bit will be lost to the void (I kind of like that).
That's all for today. Bye for now!
This website was made using Markdown, Pandoc, and a custom program to automatically add headers and footers (including this one) to any document that's published here.
Copyright © 2026 Saksham Mittal. All rights reserved. Unless otherwise stated, all content on this website is licensed under the CC BY-SA 4.0 International License